[导读] 随着高新技术在军事领域的广泛运用,武器装备逐步向高、精、尖方向发展。传统的军事训练由于训练时间长、训练费用高、训练空间窄,常常不能达到预期的训练效果,已不能满足现代军事训练的需要。为解决上述问题,模拟训练应运而生。
0 引言
随着高新技术在军事领域的广泛运用,武器装备逐步向高、精、尖方向发展。传统的军事训练由于训练时间长、训练费用高、训练空间窄,常常不能达到预期的训练效果,已不能满足现代军事训练的需要。为解决上述问题,模拟训练应运而生。
为进一步提高训练效果,本文利用智能语音交互芯片设计了某模拟训练器的示教与回放系统。示教系统为操作人员生动的演示标准操作流程及相应的操作现象,极大地缩短了对操作人员的培训时间,提高了培训效果。回放系统通过记录操作训练过程中各操作人员的口令、声音强度、动作、时间、操作现象等,待操作训练结束后通过重演训练过程,以便操作者及时纠正自己的问题。示教系统也可理解为对标准操作训练过程的回放。该系统不需要虚拟现实技术的支持,在小型的嵌入式系统上就可以实现。
1 系统原理
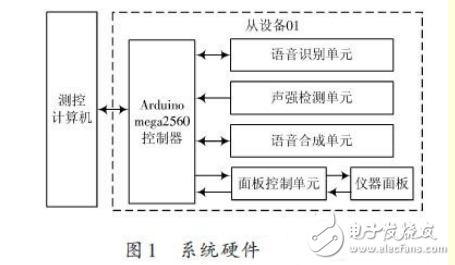
该模拟训练器由一台测控计算机和多台从设备组成。如图1所示。在此仅对一台从设备进行介绍,其硬件系统主要由测控计算机、Arduino mega2560 控制器、语音识别单元、声强检测单元、语音合成单元、面板控制单元、仪器面板等组成。面板控制单元较为复杂,包含多种控制电路,在模拟训练中负责该从设备在Arduino mega2560 控制器的控制下完成整个训练过程,在示教与回放系统中完成对刚才操作训练操作现象的重演,其具体电路设计在此不做介绍。
语音识别单元负责识别操作人员的操作口令;声强检测单元负责检测声强大小并以此作为判断是哪台从设备操作人员口令的依据;Arduino mega2560控制器负责监视仪器面板各元件的状态来识别操作人员的动作,从而完成对操作训练过程的记录。各仪器的操作现象根据操作动作事先编制无需记录。在操作回放过程中,测控计算机根据所记录的数据,通过控制相应从设备的Arduino mega2560控制器重现所记录的操作过程。
2 单元系统设计
2.1 语音识别单元设计
目前,语音识别技术的发展十分迅速,按照识别对象的类型可以分为特定人和非特定人语音识别。特定人是指识别对象为专门的人,非特定人是指识别对象是针对大多数用户,一般需要采集多个人的语音进行录音和训练,经过学习,从而达到较高的识别率。
本文采用的LD3320语音识别芯片是一颗基于非特定人语音识别(Speaker Independent Automatic SpeechRecognition,SI ASR)技术的芯片。该芯片上集成了高精度的A/D 和D/A 接口,不再需要外接辅助的FLASH 和RAM,即可以实现语音识别、声控、人机对话功能,提供了真正的单芯片语音识别解决方案。并且,识别的关键词语列表是可以动态编辑的。其语音识别过程如图2所示。
语音识别单元采用ATmega168 作为MCU,负责控制LD3320完成所有和语音识别相关的工作,并将识别结果通过串口上传至Arduino mega2560 控制器。对LD3320芯片的各种操作,都必须通过寄存器的操作来完成,寄存器读写操作有2种方式(标准并行方式和串行SPI方式)。在此采用并行方式,将LD3320的数据端口与MCU的I/O口相连。其硬件连接图如图3所示。
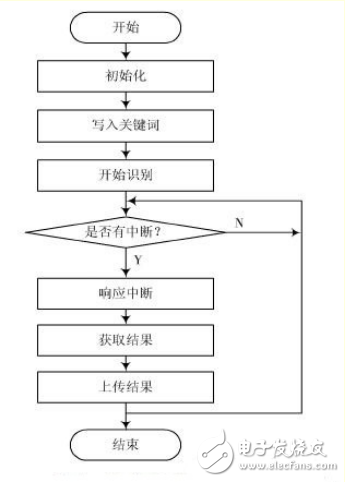
语音识别流程采用中断方式工作,其工作流程分为初始化、写入关键词、开始识别和响应中断等。MCU的程序采用ARDUINO IDE编写[5],调试完成后通过串口进行烧录,控制LD3320完成语音识别,并将识别结果上传至Arduino mega2560控制器。其软件流程如图4所示。
2.2 声强检测单元设计
在进行语音识别时需要判断是某一台从设备操作人员的口令,为此设计声强检测单元电路,该电路仅需能够判断出相对声强的大小,无需检测声级,对检测精度要求较低。
电容式MIC声音传感器将外部声音信号转换成电信号,经NE5532放大电路进行放大,将输入的微弱音频信号转换为具有一定幅值的电压信号,该电压信号经AC/DC有效值转换电路进行装换后进行再次放大,最终由Arduino mega2560控制器的A/D进行采样。图5给出了声强检测单元的电路原理图,其中D1 端接Arduinomega2560控制器的A/D,INT1端接Arduino mega2560控制器的外部中断1.当外界声音信号大于预设的阈值时,三极管导通INT1端由高电平变为低电平产生外部中断,控制器响应中断并进行 A/D 采样,采样数据经均值滤波后保存,待测控计算机查询时上传该声强数据。
2.3 语音合成单元设计
TTS(Text To Speech)文本转语音技术是人机智能对话发展的趋势。基于TTS技术的语音系统无需事先录音就能够随时根据查询条件查出并合成语音进行播报,从而大大减少了系统维护的工作量。利用此技术,通过MCU或者PC机就能控制语音芯片发音[4]。
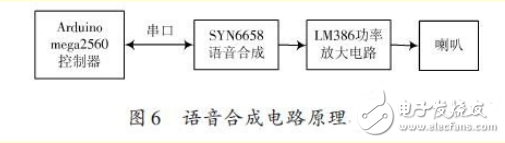
本文采用SYN6658中文语音合成芯片进行语音合成。SYN6658 通过UART 接口或SPI接口通信方式,接收待合成的文本数据,实现文本到语音(或TTS语音)的转换[6]。控制器和SYN6658 语音合成芯片之间通过UART接口连接,控制器通过串口通信向SYN6658语音合成芯片发送控制命令和文本,SYN6658语音合成芯片把接收到的文本合成为语音信号输出,输出的信号经LM386 功率放大器进行放大后连接到喇叭进行播放。如图6所示。
SYN6658语音合成电路采用芯片硬件数据手册提供的典型应用电路进行设计[5],在此不做介绍,功率放大电路采用美国国家半导体生产的音频功率放大器LM386进行放大。
在进行语音合成时首先进行初始化,包括发音人选择、数字处理策略、语速调节、语调调节、音量调节等。
由于该系统要模拟多人发音,所以不同的从设备设置不同的发音人及语调与语速以便于区分。初始化后等待测控计算机的语音合成命令,待收到命令后芯片会向上位机发送1字节的状态回传,上位机可根据这个回传来判断芯片目前的工作状态。语音合成流程图如图7所示。
3 系统软件设计
示教与回放系统的软件设计包括测控计算机的软件设计和各从设备Arduino mega260控制器的软件设计。
测控计算机是整个系统的控制核心,其软件采用C#进行编写,在示教与回放系统中主要是对操作数据的记录以便根据所记录的数据对操作过程进行精确回放,需要记录的数据包括:各从设备操作人员的操作口令,操作动作,口令及动作时间,各操作对应的操作现象。为简化记录数据,事先编制好各事件代码,记录过程只记录代码,大大提高程序效率。建立结构体如下:

在操作训练过程中测控计算机每隔50 ms 对下位机进行控制及轮询,并记录反馈数据,在数据记录时以50 ms 为一个单位。采用定时器对时间进行控制。在回放过程中首先比对当前时间和所记录的时间,当所记录的时间与当前时间吻合时测控计算机控制下位机执行该事件,完成事件回放。
Arduino mega2560控制器负责接收测控计算机的控制指令并执行指令,读取语音识别结果,对声强数据采集和处理,控制语音合成单元进行语音合成等。Arduinomega2560 控制器采用串口中断的方式进行命令接收。
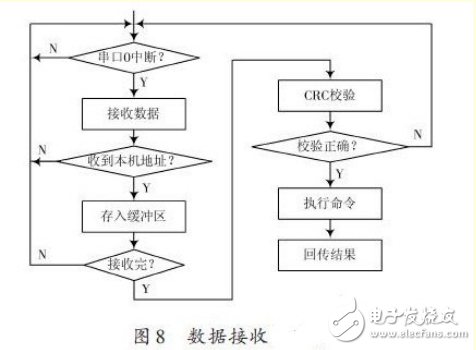
只有正确接收到命令才会执行并回传结果,若测控计算机在限定时间内未收到回传结果则表明发生错误,测控计算机需重新发送。数据接收流程图如图8所示。
4 总结
本文利用智能语音芯片设计了某模拟训练器的示教与回放系统,该系统不需要现在流行的虚拟现实技术的支持,仅在MCU的控制下就可以运行。该系统也可以在小型的便携式设备上实现,具有良好的应用前景。
|








 发表于 2015-11-20 22:27:53
发表于 2015-11-20 22:27:53





 收藏
收藏 分享
分享 支持
支持 反对
反对